

Understanding XBRL for SEC Reporting and Financial Data
If you’re a financial institution that uses data from publicly traded companies, you probably don’t think about XBRL any more than you think about the rubber used in your tires.
But XBRL represents a massive shift in financial reporting, and it has a major impact on what data you can access, how accurate that data is, and how difficult and expensive retrieving it will be for your company.
At Intrinio, we’ve been diving into this technology since our inception with the goal of becoming global XBRL industry leaders. We’ve put together a simple primer to explain what XBRL is and what that means for you.
What is XBRL?
XBRL (short for eXtensible Business Reporting Language) is an open standard for accounting data based on the programming language XML. It was created to increase the transparency and accessibility of business information.
The US GAAP Financial Reporting Taxonomy is a list of around 17,000 “tags” in XBRL that companies use to label data in financial statements. These machine-readable tags allow computers to precisely locate data for easier analysis. Since it’s extensible, companies can also “invent” their own tags if they can’t quite fit their data into the US GAAP Taxonomy.
No one owns XBRL – it’s not a software (although many third-party vendors have developed software to simplify XBRL reporting for companies). The non-profit organization XBRL International sets XBRL reporting standards. XBRL International is made up of more than 650 members, including global companies as well as accounting, technology, government, and financial services organizations.
How did XBRL start?
To make a long history short: financial statements were filed in paper format, and then PDFs, before transitioning into HTML format. HTML filing led to SEC’s Edgar database, where anyone can find the data they need, for free.
Manually. And slowly.
In 2009, the SEC mandated publicly traded companies to start filing in XBRL. Charles Hoffman, the father of XBRL, invented the language and built a robust taxonomy which provided guidelines on how to use XBRL.
Easy, right? Ha, no. Surprisingly, forcing accountants to learn programming without the right tools or education caused some hiccups. Because of the rocky implementation, lots of people were turned off of XBRL, and subsequent initiatives to mandate XBRL filing for other types of information have moved slowly because of those initial issues.
(We should know – as members of XBRL US, we’ve played a part in advocacy and lobbying for more widespread adoption of XBRL standards. The technology may not be perfect, but it’s lightyears ahead of anything we’ve used in the past.)
What’s filed in XBRL?
In the US, all publicly traded companies must file their 10-Q (quarterly) and 10-K (annual) financial statements in XBRL. Other mandatory data filed with the SEC, such as institutional holdings and insider transactions, is also in XBRL.
Energy firms such as electric and gas companies are required to file their quarterly and annual reports in XBRL with the Federal Energy Regulatory Commission (FERC). While not currently mandated in the US, some states file municipal financials in XBRL.
Globally, XBRL is a bit of a mixed bag. Most Asian countries have been filing in XBRL for 15 years. In 2020, the European Union mandated XBRL filing for European companies. Because of the uneven implementation of XBRL, it’s impossible to pull global financial data in a consistent way.
Why does it matter?
Widespread, consistent XBRL implementation has huge implications for you. Data that is (correctly) filed in XBRL is more reliable and higher quality. It increases transparency and represents major cost savings for governments, companies, and individual data users (Australia saved $1 billion in their first year of universal XBRL implementation). Plus, you get the data you need faster – think minutes instead of days or weeks.
Without XBRL, a simple misreading of the data can have catastrophic consequences. Take St. Petersburg, one of the most fiscally healthy cities in Florida (and home to one of Intrinio’s dual offices). When analysts reviewed their 300-page PDF financial statement, they couldn’t find the figure for cash, and marked it as zero. Credit agencies very nearly downgraded the city’s credit, which would have sent taxes through the roof and made it impossible for St. Petersburg to qualify for bonds for infrastructure and other projects.
This blog explains the issues with non-XBRL data in more detail.
What are the challenges with XBRL?
We’ve been defending XBRL pretty vehemently up to this point, but we’re the first to admit: it’s not perfect. Here are the biggest challenges people face with XBRL:
It’s extremely technical. As we stated earlier, XBRL is a data exchange format, which means most non-developers wouldn’t even know where to start. Heck, most developers don’t understand XBRL. Even if you want to learn, there’s very little in the way of educational resources.
It’s extensible. The “eXtensible” portion of XBRL refers to companies’ ability to extend the taxonomy – essentially, making up whatever tags they want. No two companies file statements the same way, so they could use completely different tags for the same information. That makes it difficult to compare across companies, but it also makes it a headache to compare the same companies across fiscal periods, since they can change the way they file or release new business lines that show up as brand new line items.
There are no tools. The SEC doesn’t offer the practical tools users need to work with the data, such as an API or documentation. They’re also not going to provide support if you run into an issue.
It needs a lot of work. Raw XBRL needs a ton of processing to be usable, which is why third-party data providers exist despite this data being available through the SEC for free. Providers process this data in one of two ways: by 1) hiring tens of thousands of overseas employees to map the data by hand or 2) cleaning the data with machine learning (more on this later).
What are the elements of an XBRL statement?
One of the reasons raw XBRL data is unusable is that the individual elements of an XBRL statement have to be connected programmatically. Here’s an overview of those elements:
Concepts
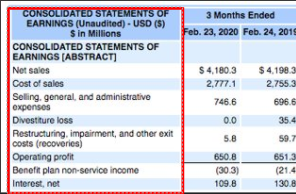
Concepts are the first column of a financial report. A grouping of these concepts (like the US GAAP one used here) is called a taxonomy. It's the collection of all the concepts and definitions.
Contexts
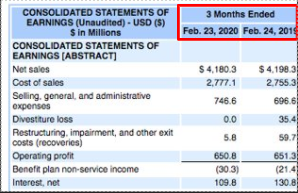
Contexts are the first column headers of a financial report, above the numbers. Generally (although not always), these are in the form of dates.
Facts
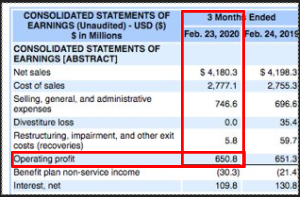
Facts are typically numbers (though they can be anything) and are defined by the intersection of a row and column.
Roles
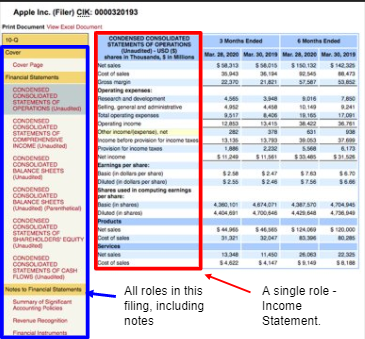
Roles are a collection of concepts. They have data for display (including the order in which they appear and the label like “Cost of sales”). Roles come in the form of Statements, Disclosures, and Notes. There are also filer-provided calculations that occur within a role that describe how numbers add up.
How does Intrinio process XBRL statements?
We mentioned earlier that XBRL data is processed in one of two ways: manually or with machine learning. Intrinio has led the charge for machine learning and developed a system for sourcing and cleaning data that doesn’t exist anywhere else in the industry.
Here’s a high-level overview of how we process XBRL data:

SEC files

Every 10-Q and 10-K (and other forms) have a set of these source files at the SEC. We download them from the SEC and store them in the cloud.
XBRL processor

According to our developers, these source files look like “someone who had been drinking heavily and then got in a knife fight.” Previously, we’ve used publicly available programming libraries (some are the same as those used at the SEC), but they are designed more for the production of XBRL, not its consumption.
We spent the last two years developing our own processor to read this data and put it into a usable format that we can put into a database.
Source data

The data coming out of the source files from the SEC has to be analyzed and parsed to create associations between bits of data. Which concepts are part of which roles? Which facts should be reported for a context? We create durable references between types of information.
Standardizer
The Intrinio XBRL Processor loads “source data” for consumption by the standardizer. As we mentioned earlier, the US GAAP taxonomy has approximately 17,000 concepts. Since companies also make up their own concepts, we’ve seen about 34,000 distinct concepts from incoming data.
Intrinio has a taxonomy of its own - data tags. There are only 296 concepts in the Intrinio taxonomy, including tags like “netincome” and “sgaexpense.” Standardization does one thing - figure out which of those 296 Intrinio concepts each XBRL concept represents.
We map a deeply hierarchal relationship between these concepts. The individual data tags have to sum up to the larger category – if they don’t, either the filing is wrong or we’re wrong. If something doesn’t add up, the data is flagged for human review. Our data quality team corrects any problematic data, and the machine learning learns from those corrections to improve the data quality over time.
Standardization solves many of the big issues with XBRL – if companies are filing differently, the standardized format will roll up those individual tags into a more general figure so you can easily compare figures like income and debt. Take, for example, our random ridiculous XBRL tag of the day:
ShortdurationInsuranceContractsLiabilityForUnpaidClaimsAndClaimsAdjustmentExpenseAccumulatedForeignExchange:
“Amount of accumulated increase (decrease) to the liability for unpaid claims and claim adjustment expenses used for claim development from a foreign exchange rate (gain) loss.”
Yeah, that goes in the “othercurrentliabilities” bucket.
Once the data is standardized, we calculate metrics that are useful to compare companies, like ROE (return on equity), ROA (return on assets), and ROI (return on investment).
We own nearly all of the technology in our process, so we have total control over the data from sourcing to publishing, and we’re constantly making improvements. This blog explains more about how we standardize our fundamentals data.
If you’re in the market for structured data from XBRL experts, explore our equities data packages, featuring our world-class fundamental data!
.jpg)
%20(1).jpg)
.jpg)



